

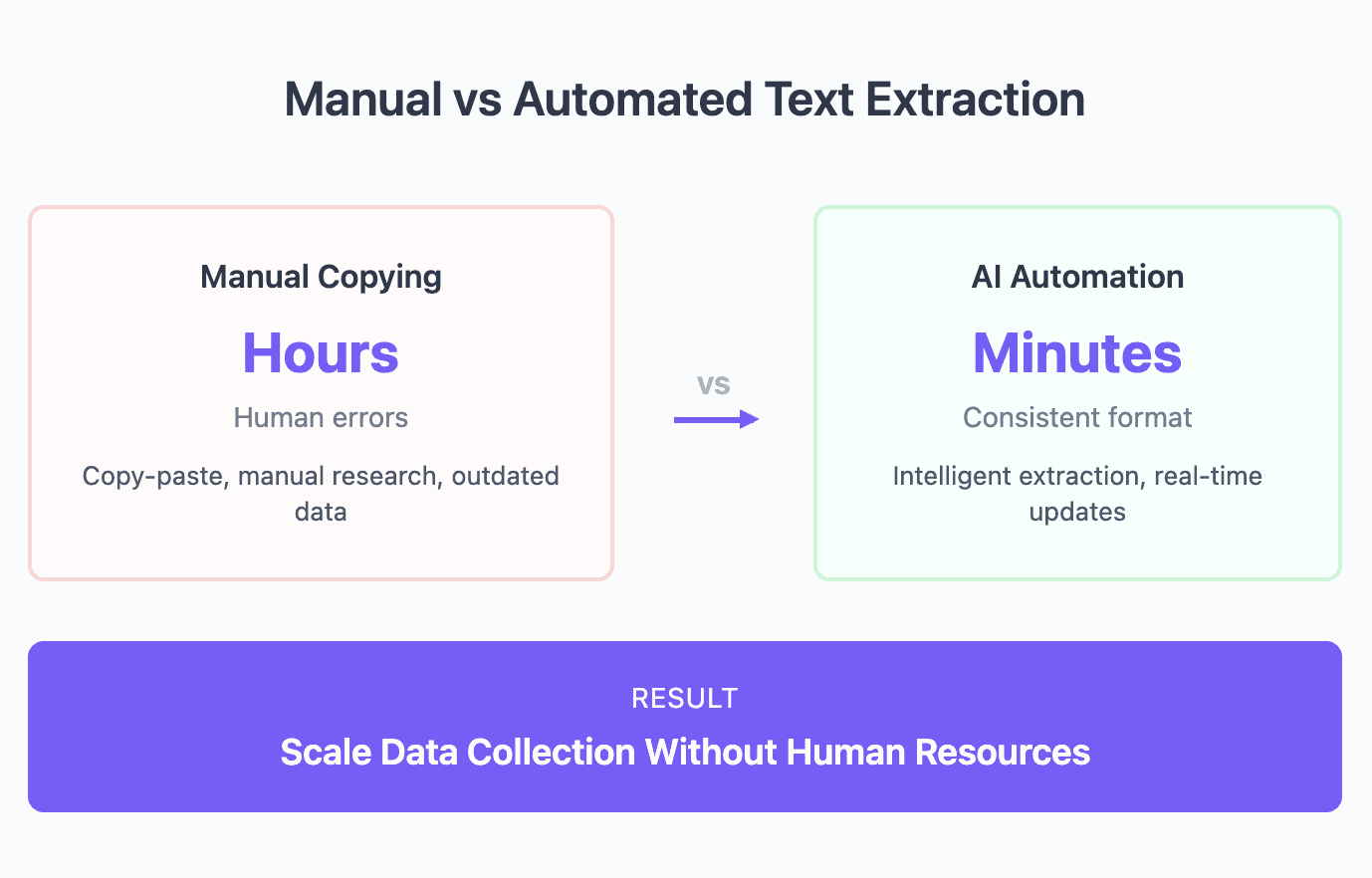
Every day, valuable business intelligence sits hidden across millions of websites – from competitor pricing and product details to customer testimonials and market trends. Yet manually copying this information wastes countless hours and often results in incomplete, outdated data.
Modern text extraction from websites has evolved far beyond simple copy-paste operations. Today's AI-powered tools can automatically identify, extract, and structure web data at scale, turning unstructured website content into actionable business intelligence.
Whether you need to monitor competitor updates, build prospect lists, or analyze market trends, this guide covers everything from basic extraction methods to advanced AI-powered solutions that automate the entire process.
What is Website Text Extraction?
Text extraction from websites refers to the process of automatically collecting and structuring textual content from web pages. This goes beyond simply scraping HTML – it involves intelligently identifying relevant information, cleaning and formatting the data, and organizing it for business use.
Modern extraction tools can handle various content types:
Product descriptions and specifications
Contact information and company details
News articles and blog posts
Reviews and testimonials
Pricing information and inventory data
Job postings and team information
The challenge isn't just grabbing text – it's extracting the right information in a usable format while respecting website terms of service and handling dynamic content that changes frequently.
Why Businesses Need Automated Text Extraction
Manual data collection from websites creates significant operational challenges. Sales teams spend hours researching prospects, copying company information, leadership details, and recent news. Marketing teams manually track competitor pricing, product updates, and content strategies. Research teams compile market data from hundreds of sources, often missing critical updates.
Automated text extraction solves these problems by:
Saving time and resources – What takes hours manually can be completed in minutes automatically. Teams can focus on analyzing data rather than collecting it.
Ensuring data accuracy – Automated extraction eliminates human error from manual copying and provides consistent formatting across all collected data.
Enabling real-time monitoring – Track changes across thousands of websites simultaneously, catching updates as they happen rather than during periodic manual checks.
Scaling data collection – Extract information from hundreds or thousands of pages without additional human resources.
Creating competitive advantages – Access to comprehensive, up-to-date web data enables better decision-making and faster response to market changes.
Methods to Extract Text from Websites
1. Browser Extensions and Basic Tools
The simplest approach to extract text from website pages uses browser extensions and online tools. These solutions work well for occasional, small-scale extraction needs.
Copy-paste with formatting tools remain the most basic option. Modern browsers offer "Reader Mode" features that strip away navigation and ads, making manual copying cleaner. Tools like Mercury Reader or Clearly enhance this process by better preserving content structure.
Browser extensions like Databar.ai’s Chrome Extension, Web Scraper, or Simple Scraper add point-and-click extraction capabilities. Users can select elements on a page and extract similar content across multiple pages. While limited in scale, these tools require no coding knowledge.
Online extraction services provide quick solutions for one-off needs. Sites like ParseHub's magic tool or Import.io's basic extractor let users paste URLs and receive extracted text. However, these typically handle only simple, static pages.
2. Web Scraping with Programming
For more control and scale, developers use programming languages to extract text from websites. This approach offers maximum flexibility but requires technical expertise.
Python with BeautifulSoup remains the most popular choice for custom scraping. This combination handles HTML parsing effectively and integrates well with data processing libraries. A basic BeautifulSoup script can extract specific elements from thousands of pages.
JavaScript with Puppeteer excels at handling modern websites with dynamic content. Since Puppeteer controls a real browser, it can wait for JavaScript to load, click buttons, and navigate complex sites that static scrapers can't handle.
Scrapy framework provides a complete solution for large-scale extraction projects. It handles request scheduling, data pipelines, and error handling automatically. Professional scraping operations often build on Scrapy's robust architecture.
3. API-Based Extraction Services
Cloud-based APIs offer a middle ground between simple tools and custom development. These services handle the technical complexity while providing programmatic access.
ScrapingBee and ScraperAPI manage proxy rotation, browser rendering, and anti-bot detection automatically. Developers send URLs and receive extracted content through simple API calls. This approach scales well without infrastructure management.
Diffbot uses computer vision and natural language processing to understand page content semantically. Rather than relying on HTML structure, it identifies articles, products, and other content types automatically.
Bright Data (formerly Luminati) provides enterprise-grade infrastructure for large-scale extraction. Their residential proxy network and advanced tools handle even heavily protected sites.
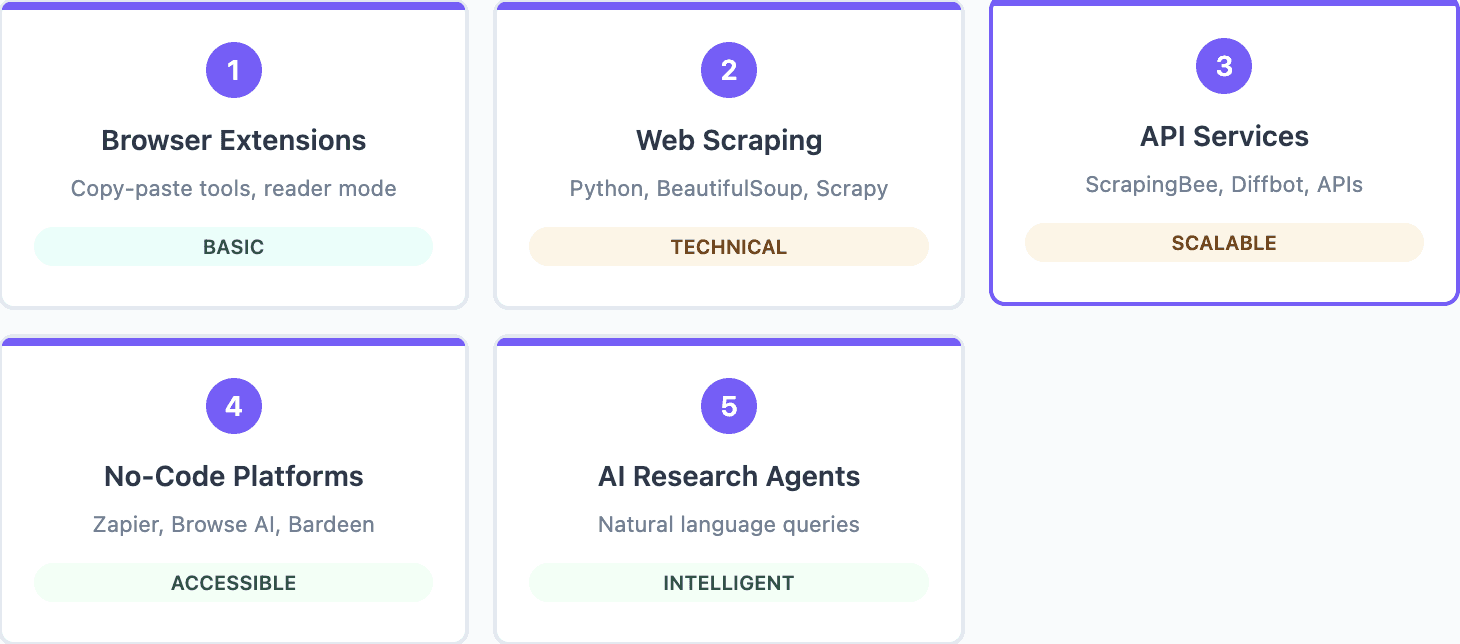
4. No-Code Automation Platforms
Modern no-code platforms democratize web data extraction, making it accessible to non-technical users while maintaining professional capabilities.
Zapier and Make (formerly Integromat) include web scraping modules in their automation workflows. Users can extract data from websites and immediately send it to spreadsheets, CRMs, or other applications without coding.
Bardeen specializes in browser automation, including text extraction. Its AI-powered scraper can understand page content and extract relevant information based on natural language instructions.
Browse AI trains custom robots through recording user interactions. Once trained, these robots can extract data from complex sites repeatedly, adapting to minor layout changes automatically.
5. AI-Powered Research Agents
The latest evolution in web text extraction uses AI agents that understand context and can research like humans do. These tools go beyond simple extraction to provide intelligent data gathering.
Databar.ai's AI Research Agent represents this new generation. Unlike traditional scrapers that need exact instructions, you can ask it natural language questions like "Find this company's main product features" or "What customer pain points do they address?" The AI agent then:
Searches across multiple pages to find relevant information
Understands context to extract meaningful insights
Structures findings in immediately usable formats
Handles complex research tasks that would typically require human analysis
This approach transforms text extraction from websites from a technical task into a business research function, making it accessible to sales, marketing, and research teams without technical expertise.
Now that we've covered the evolution of extraction methods, let's dive deeper into how AI research agents actually work and why they represent the future of web data extraction.
Detailed Guide on Text Extraction with AI Research Agents
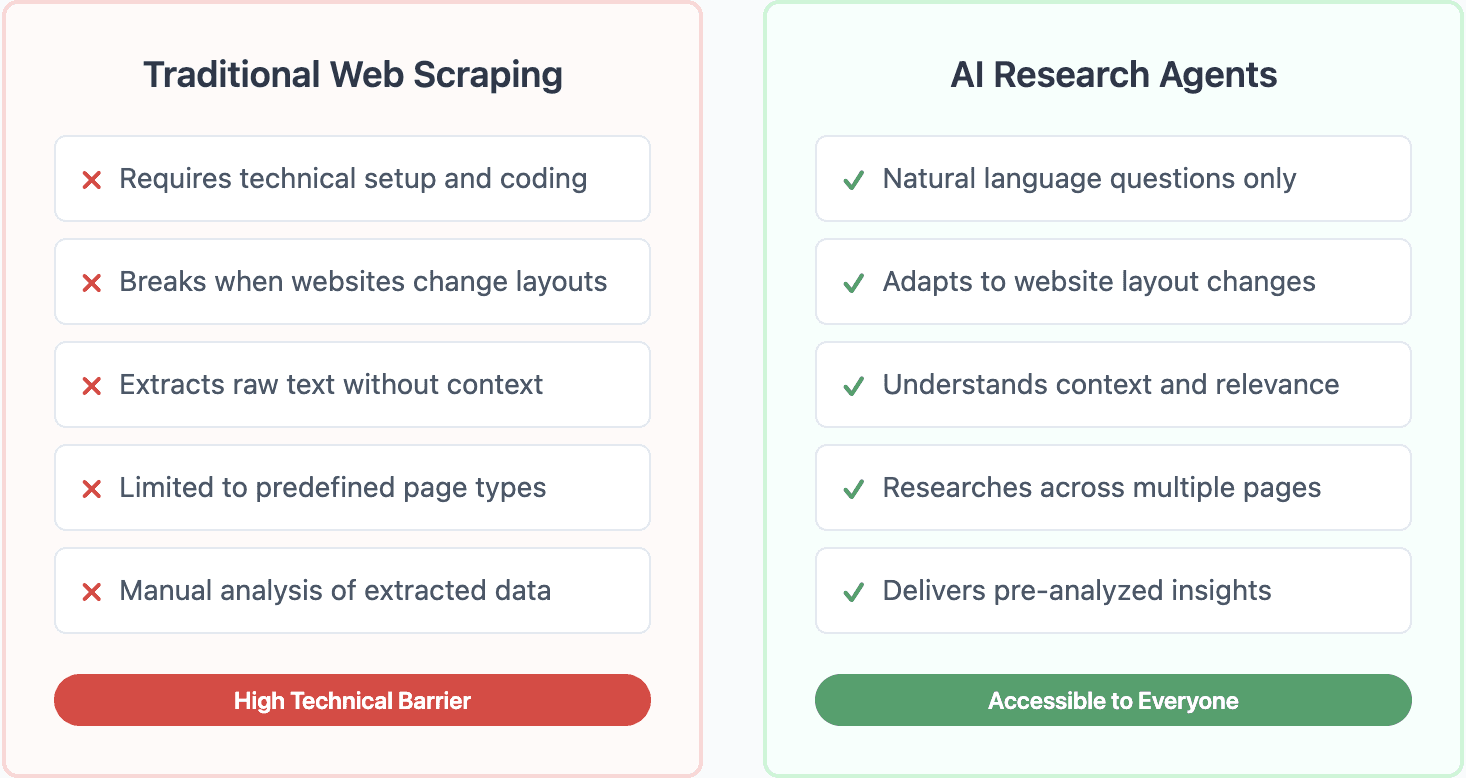
Traditional web scraping tools require precise instructions about what to extract and where to find it. AI research agents optimize this process by understanding intent and context, enabling more sophisticated data gathering.
How AI Research Agents Work
Modern AI agents like Databar.ai's research assistant combine several technologies to deliver human-like research capabilities. When you ask a question like "What are this company's main competitive advantages?" the AI:
Understands the research intent by processing natural language to determine what information would answer your question. It identifies relevant concepts and relationships to guide its search.
Navigates websites intelligently by analyzing page structures to find relevant sections, following internal links to discover related content, and prioritizing high-value pages based on content relevance.
Extracts contextual information through advanced natural language processing that understands meaning beyond keywords, identifies relationships between different pieces of information, and distinguishes between primary and supporting details.
Synthesizes findings by combining information from multiple sources, resolving conflicting data points, and structuring results in actionable formats.
So, what do practical applications look like?
Let's walk through how a sales rep uses Databar.ai's AI agent to extract customer testimonials from prospect websites for personalized outreach:
Step 1: The Ask: Instead of manually browsing through prospect websites looking for testimonials, she simply asks: "Visit the company website and extract all available testimonials along with the companies/individuals who provided them."
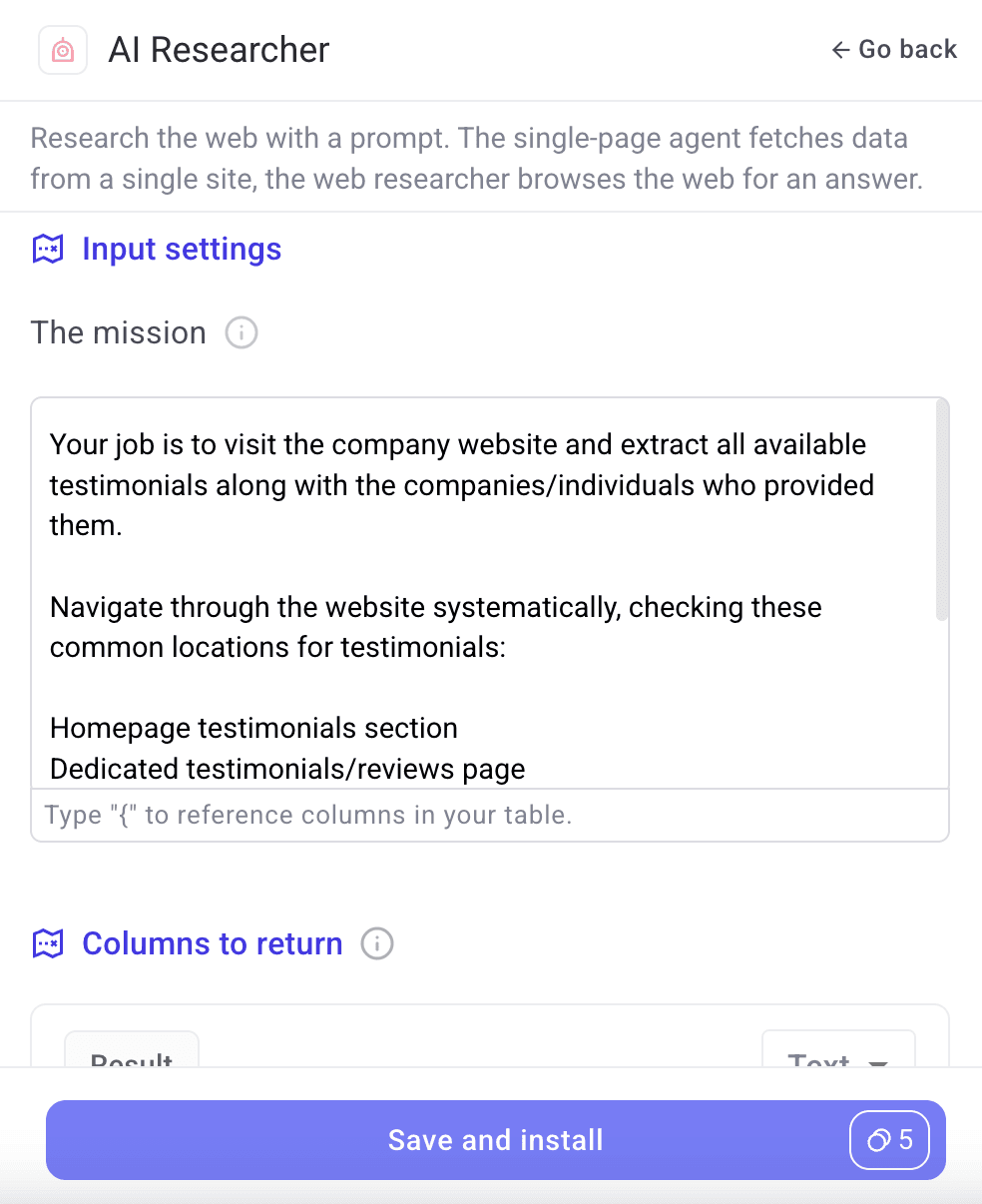
Step 2: Automatic Research The AI agent automatically:
Navigates through the website systematically
Checks common testimonial locations (homepage sections, dedicated reviews pages)
Extracts both the testimonial content and attribution details
Identifies the person's name, title, and company for each testimonial
Step 3: Synthesized Results Within minutes, she receives structured data showing:
Testimonial content: "Databar has completely changed how we handle data enrichment for our outbound campaigns"
Attribution: Finn Hoenig, CEO, Shary
Additional testimonials: From Growth Consultant at Seedbox and CEO at Roopairs
Context for outreach: Ready-to-use social proof and conversation starters
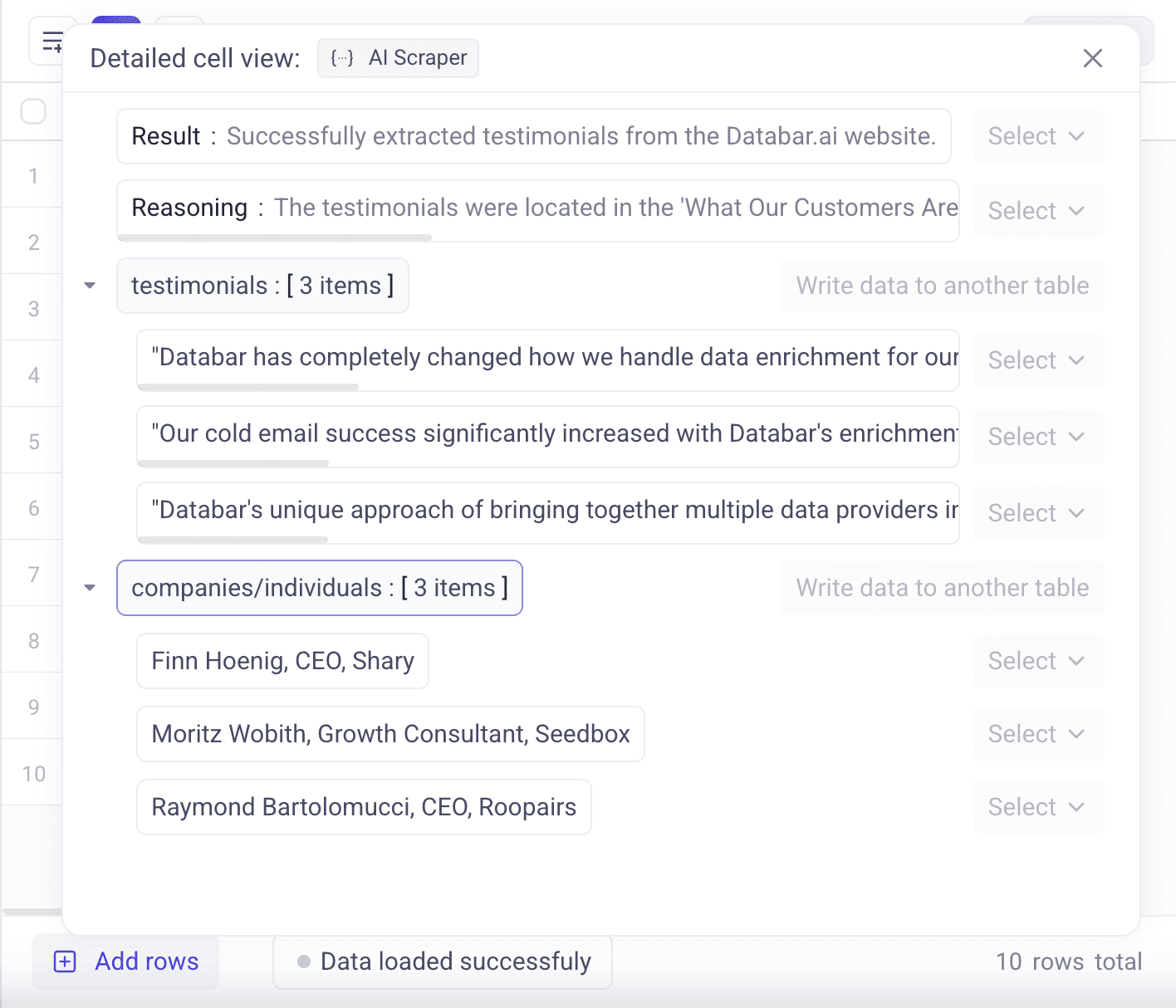
The Result: What would have taken 30+ minutes of manually browsing websites and copying testimonials is completed in under 1 minute. The sales rep now has authentic customer success stories to reference in outreach, plus specific contact details of satisfied customers who might provide referrals or case study opportunities.
This extracted testimonial data becomes the foundation for highly personalized first lines like: "I saw you helped CompanyX with Y and achieved great Z results for them. Are you interested in finding similar companies like CompanyX that fit your ICP perfectly?"
What Are Benefits Over Traditional Extraction?
AI research agents offer several benefits compared to traditional web scraping:
No technical setup required – Users simply ask questions in plain English rather than defining CSS selectors or XPath expressions. This democratizes access to web data across entire organizations.
Adaptive to website changes – AI agents understand content semantically, so they continue working even when website layouts change. Traditional scrapers break whenever HTML structure changes.
Contextual understanding – Rather than blindly extracting text, AI agents understand relevance and relationships. They can determine what information actually answers your question.
Cross-page research – AI agents automatically navigate between related pages to compile complete answers. Traditional scrapers require explicit programming for each page type.
Immediate insights – Results come pre-analyzed and structured, not as raw text requiring processing. AI agents deliver actionable intelligence, not just data.
Best Practices for Website Text Extraction
Start with Clear Objectives
Before beginning any extraction project, define exactly what information you need and why. This clarity helps choose the right tools and methods while avoiding scope creep that wastes resources.
Document your requirements including target websites and update frequency, specific data fields needed, acceptable accuracy levels, and budget constraints. This preparation prevents costly mistakes and ensures sustainable extraction processes.
Choose the Right Tool for Your Needs
Match your extraction method to your specific requirements. For occasional extractions from a few sites, browser extensions or online tools suffice. Regular extraction from known sites benefits from no-code platforms. Large-scale or complex extraction projects may require custom development or enterprise solutions.
Consider factors like technical expertise available, volume and frequency of extraction, complexity of target websites, budget for tools and development, and integration requirements with existing systems.
Implement Proper Error Handling
Website structures change frequently, breaking extraction processes. Build resilience through validation checks for extracted data, alerts for extraction failures, fallback methods for common issues, and regular testing of extraction workflows.
Document all extraction logic thoroughly, making it easier to update when sites change. Store multiple versions of selectors or patterns to handle variations across similar pages.
Plan for Maintenance and Updates
Extraction systems require ongoing maintenance. Websites change layouts, implement new protections, or modify their data structures. Build maintenance into your process through regular audits of extraction accuracy, monitoring for website changes, documented update procedures, and backup extraction methods.
Consider the total cost of ownership, including maintenance time, when choosing between build-versus-buy options.
Turn Web Data into Business Intelligence
Extracting text from websites has evolved from a technical challenge into an accessible business capability. Whether you need competitor intelligence, market research, or prospect information, modern tools make web data extraction achievable for any organization.
For teams ready to move beyond basic scraping to intelligent research, Databar.ai offers a revolutionary approach. Our AI research agent understands your business questions and automatically extracts relevant insights from any website.
See the difference AI-powered extraction makes:
✓ Ask natural language questions instead of defining technical selectors
✓ Get synthesized insights not just raw extracted text
✓ Research across multiple pages automatically
✓ Access 90+ data sources beyond just web scraping
✓ Build complete prospect profiles with extracted and enriched data
Stop wasting hours manually copying information from websites. Start your free Databar.ai trial and transform web data into actionable intelligence in minutes.
Frequently Asked Questions
Is it legal to extract text from websites? Extracting publicly available text is generally legal, but you must respect robots.txt files, website terms of service, and avoid extracting personal data. Always implement reasonable rate limits and consider reaching out to website owners for permission when extracting significant amounts of data. Focus on publicly accessible business information rather than gated or personal content.
What's the difference between web scraping and using an AI research agent? Web scraping requires technical setup to extract specific elements from web pages, often breaking when sites change. AI research agents understand natural language questions and can navigate sites intelligently to find relevant information. While scraping extracts raw data, AI agents provide analyzed insights and can research across multiple pages automatically.
How do I handle websites with dynamic JavaScript content? Dynamic content requires tools that can execute JavaScript. Use headless browsers like Puppeteer, choose extraction services that handle JavaScript rendering, or identify API endpoints serving the data. Modern AI research agents and professional extraction tools handle dynamic content automatically without requiring technical configuration.
What's the best way to extract text from multiple websites at scale? For scaling extraction across many sites, use cloud-based services that handle infrastructure, implement parallel processing to extract from multiple sites simultaneously, and choose tools with built-in error handling and retries. AI research agents like Databar.ai’s can research multiple websites based on a single question, automatically handling the complexity of different site structures.
Recent articles
See all





