

Bottom Line Up Front: Finding a reliable Reddit scraper that actually works isn't as simple as most articles make it seem. Most tools break under pressure, hit rate limits immediately, or deliver messy data that's unusable for real analysis. In this article we’ll cover the tools that consistently deliver results.
Reddit hosts over 430 million monthly active users across 100,000+ active communities, making it one of the internet's largest sources of genuine user discussions. Unlike other social platforms where algorithms control what you see, Reddit's upvote system means the most valuable content naturally rises to the top.
Why Reddit Data Extraction Matters
Reddit represents something totally unique in the social media world. While other platforms serve up curated content designed to keep you scrolling, Reddit delivers raw, unfiltered conversations about virtually every topic you can imagine. This makes it incredibly valuable for brand monitoring, competitive intelligence, and customer research.
I've watched companies discover that Reddit discussions often predict market trends months before they appear elsewhere. The platform's community-driven structure means users share brutally honest opinions about products, services, and brands without the filtered messaging you see on other platforms.
Brand reputation management becomes crucial when Reddit users can make or break product launches through viral discussions. A single popular post criticizing a product can reach millions of users and completely tank purchasing decisions. On the flip side, positive community feedback can drive explosive growth for companies that engage authentically.
Competitive intelligence flows naturally from Reddit's discussion format. Users regularly compare products, share experiences with different services, and discuss pricing across various solutions. This creates a massive treasure trove of insights for companies monitoring their competitive landscape.
Customer research happens organically as users describe pain points, suggest improvements, and detail their decision-making processes. Product teams have found Reddit discussions more valuable than expensive focus groups because the feedback is completely unsolicited and genuine.
The challenge? Extracting this valuable data systematically and at scale. Reddit's structure makes manual monitoring impossible for comprehensive coverage, while the platform's anti-automation measures make basic scraping approaches totally unreliable. Similar challenges exist with YouTube data extraction, requiring sophisticated approaches for reliable social media intelligence.

What Separates Tools That Work from Complete Disasters
Not all Reddit scrapers are created equal. The difference between tools that actually work and those that'll make you want to throw your laptop out the window comes down to several critical factors.
Reliability stands above everything else. Reddit frequently updates its interface and implements new anti-bot measures. Scrapers that worked perfectly last month can suddenly become completely useless overnight. The best tools adapt automatically to these changes without you having to fix anything.
Data quality often matters way more than quantity. Many scrapers extract massive amounts of malformed data that requires hours of cleanup before you can actually use it. Well-designed tools provide clean, structured output that's immediately usable for business intelligence or research purposes.
Ease of setup determines whether you'll actually use the thing. Teams often choose powerful tools with complex configurations, then never implement them because setup takes forever. The most successful Reddit scraping projects use tools that balance capability with simplicity.
Scalability requirements vary dramatically between use cases. Monitoring a few specific keywords requires different capabilities than comprehensive subreddit analysis. The best scrapers handle both scenarios without breaking or requiring complete reconfiguration. These same reliability principles apply to [Instagram scraping tools] that must adapt to platform changes automatically.
Integration capabilities determine actual business value. Tools that dump raw CSV files create additional work, while solutions that connect directly to existing business systems provide immediate actionable insights.
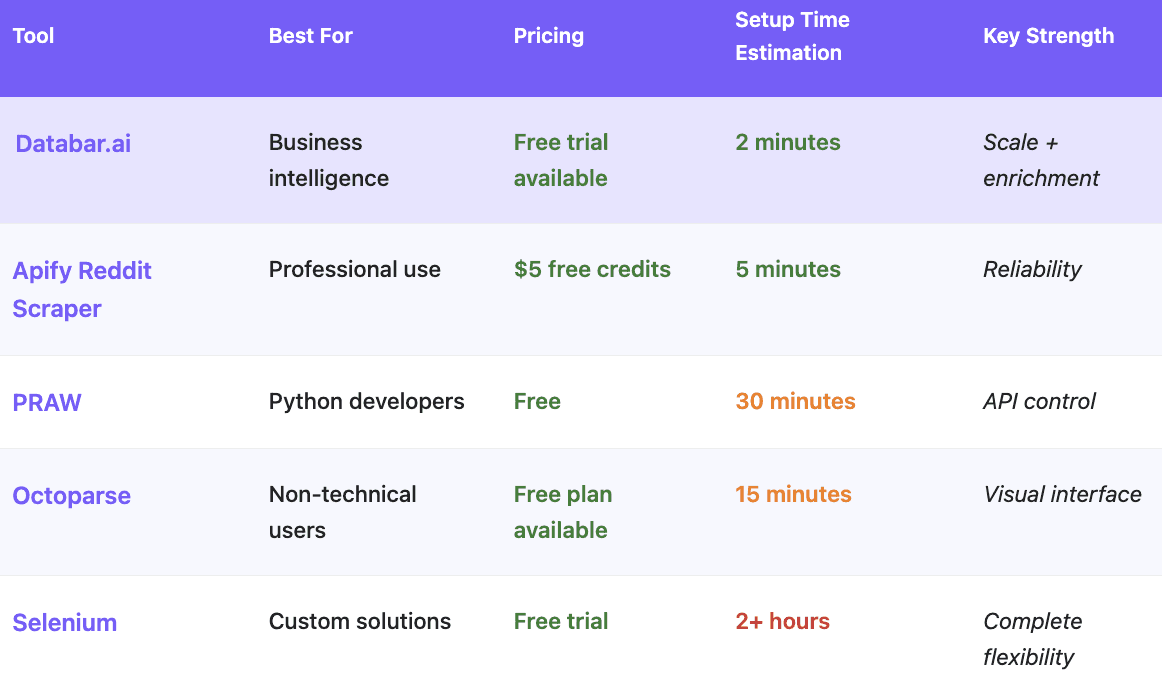
1. Databar
Databar approaches Reddit scraping completely differently by treating data extraction as part of a complete business intelligence workflow rather than just grabbing text from web pages. When you extract Reddit mentions, the platform automatically enriches that data with company information, contact details, and competitive intelligence from over 90 premium data providers.
This integrated approach eliminates the typical nightmare of extracting Reddit data, then manually researching companies and contacts mentioned in discussions. Instead, you get complete prospect profiles immediately, including business context that makes Reddit mentions actually actionable.
The setup process takes literally minutes rather than hours. Create a new table, select "Search Reddit posts," enter your keywords, and run the extraction. Results include post content, engagement metrics, author information, and subreddit context in a familiar spreadsheet interface that doesn't require a computer science degree to understand.
Data enrichment happens automatically when Databar identifies companies or individuals mentioned in Reddit discussions. The platform pulls firmographic data, contact information, technology stack details, and competitive intelligence to create comprehensive business profiles without you lifting a finger.
Workflow automation triggers targeted actions based on Reddit insights. Identify prospects showing buying intent, respond to customer support requests, or launch personalized outreach campaigns using Reddit context for way higher engagement rates than generic cold emails.
The platform absolutely excels for business-focused use cases like brand monitoring, competitive intelligence, and lead generation. Teams needing Reddit data for academic research or casual analysis might prefer more technical alternatives, but for business applications, this approach is game-changing.
Best for: Marketing teams, sales professionals, and business analysts who need Reddit insights connected to actionable business intelligence
2. Apify Reddit Scraper

The Apify Reddit Scraper consistently delivers reliable results across different Reddit sections and use cases. Built on Apify's robust cloud infrastructure, this tool handles Reddit's complexity through professionally maintained extraction logic that adapts to platform changes automatically.
Actor-based architecture means you're accessing a tool designed specifically for Reddit rather than some generic web scraping thing that breaks constantly. The scraper understands Reddit's structure, handles rate limiting intelligently, and provides clean, structured output without requiring technical configuration.
Extraction capabilities cover posts, comments, user information, and media content from any subreddit or user profile. The tool works without Reddit authentication, making it accessible for teams that need data extraction without API complications or developer accounts.
Cloud execution prevents common blocking issues by rotating IP addresses and simulating realistic browsing patterns. Schedule extractions to run automatically, then access results through multiple export formats or direct API integration with your existing systems.
Data output includes comprehensive metadata like timestamps, vote counts, author karma, post URLs, and comment threading information. The structured format works immediately with popular analysis tools and business applications without requiring data transformation.
Pricing starts at $5 in monthly credits for the free plan, typically covering about 1,000 extracted results. Professional plans begin at $49/month for regular business usage with higher extraction limits and priority support that actually responds quickly.
The tool works well for both technical and non-technical users, offering simple configuration for immediate results while supporting advanced customization for complex requirements.
Best for: Businesses needing reliable, scalable Reddit data extraction with professional maintenance and support
3. PRAW (Python Reddit API Wrapper)
PRAW provides direct access to Reddit's official API through clean Python interfaces, making it the preferred choice for developers building custom Reddit integration or analysis systems.
Official API access means working within Reddit's intended framework rather than trying to circumvent restrictions. This approach provides better long-term stability and compliance, though with usage limitations imposed by Reddit's API terms that have gotten stricter recently.
Development flexibility allows custom logic for filtering, processing, and integrating Reddit data with existing applications. Extract specific data types, implement custom rate limiting, or build real-time monitoring systems tailored to exact requirements that other tools can't handle.
Authentication system supports both read-only access for public data and authorized access for user-specific information. The wrapper handles API complexities like rate limiting, error recovery, and request formatting automatically, so you don't have to deal with the technical details.
Setup requires Python knowledge and Reddit API credentials obtained by registering an application. Comprehensive documentation and community examples help developers get started quickly, though you'll need actual programming skills to make this work.
Cost remains free since PRAW uses Reddit's official API, but you must comply with Reddit's usage limits and terms of service. Commercial applications may require special permissions from Reddit, and the recent API changes have made some previously free use cases expensive.
Best for: Python developers, data scientists, and technical teams needing custom Reddit integration or advanced data processing capabilities
4. Octoparse
Octoparse eliminates coding requirements through its visual point-and-click interface that builds extraction logic by observing user interactions with Reddit pages. This approach makes complex data extraction accessible to non-technical users.
Visual workflow creation works by navigating to Reddit pages and clicking on elements you want to extract. Octoparse records these actions and converts them into repeatable extraction workflows that handle pagination, infinite scrolling, and dynamic content loading automatically.
Template system provides pre-built extraction patterns for common Reddit data types like subreddit posts, comment threads, and user profiles. You can customize templates for specific needs or build completely custom workflows from scratch without touching any code.
Cloud extraction prevents IP blocking by executing extractions on Octoparse's servers with automatic proxy rotation and realistic browsing simulation. Schedule extractions to run automatically and receive results via email or direct download to your preferred location.
Data export options include Excel, CSV, JSON, and direct database connections. Integration capabilities support popular business tools through APIs and webhook connections that work with most existing workflows.
Free plan includes 10,000 records per export with basic features, while paid plans start at $75/month for advanced capabilities like unlimited extractions, API access, and priority cloud processing that actually works reliably.
Best for: Business analysts, researchers, and marketers who need Reddit data extraction without programming skills or technical infrastructure
5. Selenium WebDriver
Selenium handles Reddit extraction scenarios that other tools simply can't address by providing complete browser automation capabilities. This approach works when you need to interact with JavaScript elements, handle infinite scrolling, or extract content that loads dynamically.
Browser automation simulates real user interactions, making it possible to extract content exactly as a human visitor would see it. This capability becomes essential for comprehensive data collection from Reddit's increasingly dynamic interface that breaks simpler tools.
Customization possibilities are basically unlimited since Selenium provides direct browser control. Implement complex interaction patterns, handle authentication flows, or extract data from specialized Reddit interfaces that standard scrapers can't access at all.
Programming requirements include knowledge of Python, Java, or other supported languages. You'll need to manage browser drivers, implement element selection logic, and handle error recovery for robust extraction systems that don't break constantly.
Infrastructure costs vary based on extraction scale. While Selenium itself is free, running browser instances requires significant computing resources for large-scale operations, especially when you need to avoid detection.
Maintenance overhead includes updating extraction logic as Reddit's interface changes and managing browser compatibility across different systems. This can become a full-time job for complex implementations.
Best for: Developers building highly customized solutions, teams with specific requirements that other tools can't meet, and academic researchers needing comprehensive data extraction
6. Universal Reddit Scraper (URS)
URS provides powerful extraction capabilities through a Python-based command-line interface that makes PRAW functionality accessible to users who prefer terminal-based tools and automation scripts.
Command-line efficiency appeals to users comfortable with terminal interfaces and automation workflows. Extract posts, comments, and user data with simple commands that can be integrated into larger data processing pipelines without GUI overhead.
CSV output formatting creates structured data files ready for analysis in Excel, R, Python, or other analytical tools. The organized format includes comprehensive metadata with proper data type handling that doesn't require additional cleanup.
Open-source nature means completely free usage with access to source code for customization. The active community provides support, updates, and feature enhancements through GitHub contributions and discussions.
Python environment requirement means you need basic Python setup and Reddit API credentials. Installation involves configuring Python packages and obtaining appropriate API access, which takes some technical knowledge.
Best for: Students, academic researchers, and budget-conscious users with basic Python skills who need reliable Reddit data extraction
7. ParseHub
ParseHub's visual approach makes complex Reddit extraction accessible through point-and-click workflow building that records user actions and converts them into repeatable extraction patterns.
Browser-based workflow creation lets you navigate to Reddit pages and build extraction logic by interacting with page elements. ParseHub observes your actions and creates extraction workflows that can handle pagination, form interactions, and dynamic content loading.
Pagination handling works particularly well with Reddit's infinite scrolling and "load more" button patterns that often break simpler extraction tools. The visual workflow builder makes it easy to configure these complex interactions without writing code.
Cloud execution provides extraction processing on ParseHub's servers with automatic proxy rotation and realistic browsing patterns to avoid blocking. This approach handles the technical complexity while you focus on configuration.
Free plan supports basic extractions with limitations on pages and workflow complexity. Paid plans start around $149/month for professional features and higher extraction volumes with priority processing.
Best for: Marketing teams needing custom extraction workflows, agencies serving multiple clients, and users who prefer visual configuration over programming
8. ScrapeOwl
ScrapeOwl provides Reddit scraping through a simple API that handles all the complexity of browser automation, proxy management, and anti-detection measures behind the scenes.
API simplicity means sending HTTP requests with your target URLs and receiving clean JSON responses containing extracted data. This approach eliminates browser setup, proxy configuration, and maintenance headaches that plague other solutions.
Anti-detection capabilities include automatic CAPTCHA solving, proxy rotation, and browser fingerprint randomization that keeps your scraping operations running smoothly without interruption.
JavaScript rendering ensures you capture all content that loads dynamically, including Reddit's infinite scroll features and comment threads that load on demand.
Pay-per-request pricing starts with 1,000 free requests monthly, then scales based on usage. This model works well for variable extraction needs without committing to fixed monthly costs.
Best for: Developers needing simple API integration, teams with variable extraction requirements, and projects requiring reliable anti-detection capabilities
9. Bright Data
Bright Data offers enterprise-grade web scraping infrastructure with specific optimizations for social media platforms including Reddit. This solution handles large-scale extraction requirements that overwhelm smaller tools.
Proxy network includes millions of IP addresses across residential and datacenter infrastructure, providing the scale and reliability needed for comprehensive Reddit monitoring without blocking issues.
Compliance features include built-in respect for robots.txt, rate limiting, and data protection measures that meet enterprise security and legal requirements for commercial data collection.
Professional services include custom scraper development, ongoing maintenance, and technical support that handles the complexity of large-scale Reddit extraction projects.
Enterprise pricing reflects the comprehensive nature of the service, typically starting at several thousand dollars monthly for serious business applications with guaranteed SLAs and dedicated support.
Best for: Large enterprises with substantial Reddit monitoring requirements, companies needing guaranteed compliance, and organizations requiring custom extraction development
10. Reddit API
Reddit's official API provides the most compliant method for accessing Reddit data, though recent changes have made it more restrictive and expensive for many business applications.
Official compliance reduces legal risks and ensures long-term access stability for applications that can work within API limitations. This approach works best for research projects and applications where compliance matters more than comprehensive data access.
Structured endpoints provide clean, reliable data with official support for common use cases like post retrieval, comment extraction, and user information access. The data format is well-documented and stable.
Authentication requirements include application registration and API key management. Reddit reviews commercial applications and may require special permissions for business use cases, especially high-volume applications.
Recent pricing changes have made high-volume API access expensive, with many previously free use cases now requiring paid subscriptions starting at hundreds of dollars monthly for serious business usage.
Best for: Applications requiring official compliance, research projects with institutional backing, and businesses willing to pay for official API access
Choosing the Right Reddit Scraper for Your Needs
The best Reddit scraper depends entirely on your specific requirements, technical capabilities, and business constraints. Here's how to choose based on common scenarios:
For business intelligence and lead generation, Databar provides the most complete solution by combining Reddit extraction with automatic data enrichment and business system integration. This approach delivers immediate actionable insights rather than raw data requiring additional processing. Similar business intelligence capabilities exist with Facebook scraping approaches for comprehensive social media monitoring.
For reliable professional extraction without extensive technical setup, Apify offers the best balance of simplicity and capability. The cloud-based approach handles Reddit's complexity automatically while providing professional-grade reliability.
For custom development projects requiring full control, PRAW gives developers direct access to Reddit's official API with maximum flexibility for custom implementations that other tools can't provide.
For non-technical teams needing regular Reddit monitoring, Octoparse provides powerful visual extraction capabilities without programming requirements or infrastructure management.
For budget-conscious projects with basic technical capabilities, URS delivers surprisingly robust extraction functionality completely free through its command-line interface.
Consider these factors when making your decision: technical expertise available on your team, budget constraints including both tool costs and implementation time, data requirements such as extraction volume and complexity, compliance needs regarding official API access versus web scraping approaches, integration requirements with existing business systems, and ongoing maintenance capabilities for tool updates and configuration changes.
Advanced Strategies for Reddit Data Extraction
Start with focused keyword monitoring before expanding to subreddit analysis. Begin with specific brand mentions, competitor names, or industry terms to understand data patterns and volume before scaling up extraction scope to avoid overwhelming your analysis capabilities.
Combine multiple data sources for comprehensive business intelligence. Reddit provides sentiment and conversation context, but enriching with company data, contact information, and competitive intelligence creates actionable business insights rather than just social media monitoring data. Apply similar enrichment strategies to Instagram data analysis for complete cross-platform social intelligence.
Implement proper rate limiting to maintain long-term access reliability. Reddit's anti-spam measures have become increasingly sophisticated, and tools that ignore these limitations often face permanent blocking that makes them useless for ongoing projects.
Focus on data quality over extraction volume. Clean, relevant data from targeted sources provides more business value than massive datasets with poor signal-to-noise ratios that require extensive filtering and cleanup before analysis.
Plan for Reddit interface changes by choosing tools with active maintenance and automatic adaptation capabilities. Reddit regularly updates its structure, and extraction tools that break with every change aren't sustainable for business applications.
Consider legal and ethical implications carefully. While publicly available data collection is generally permissible, always review relevant terms of service and consider the ethical implications of your specific data use cases.

Frequently Asked Questions
What's the most reliable Reddit scraper available in 2025? Based on extensive analysis, Apify Reddit Scraper and Databar provide the highest reliability for professional use cases, maintaining consistent functionality even during Reddit platform updates. For business applications requiring additional data enrichment, Databar combines reliable extraction with automatic business intelligence enhancement.
Can you scrape Reddit data without paying for tools? Yes, several free options exist. PRAW uses Reddit's official API at no cost but with usage limitations. Universal Reddit Scraper (URS) provides command-line extraction capabilities completely free. Selenium offers unlimited flexibility but requires significant technical implementation effort.
Is Reddit data extraction legal for business use? Generally yes for publicly available data, but you must comply with Reddit's Terms of Service and applicable regulations. Using the official API provides the most compliant approach. Web scraping public data is typically legal but may violate platform terms. Always consult legal counsel for commercial applications.
What's the difference between Reddit API access and web scraping? Reddit's API provides official structured access but has strict rate limits and recent pricing increases for commercial use. Web scraping accesses Reddit like a browser, potentially gathering more data but risking terms of service violations. API access offers better compliance; web scraping provides more flexibility.
Can you extract Reddit comments and nested reply structures? Yes, but capability varies significantly between tools. Apify and Databar handle complex comment hierarchies well, preserving conversational context and threading. Simpler scrapers often flatten comment structures, losing the discussion flow that makes Reddit conversations valuable for analysis.
What types of data can you extract from Reddit? You can extract post titles, content, author information, timestamps, vote counts, comment threads, subreddit details, engagement metrics, user karma, post flair, and media links. The exact data availability depends on your chosen tool and Reddit's current platform structure.
Recent articles
See all





